

Aprenda qué es un lago de datos, las diferencias con respecto a un almacén de datos, los casos de uso, la gobernanza y cómo transformar datos sin procesar en información útil.
En los últimos años, empresas de todos los tamaños se han enfrentado a un desafío común: lidiar con la cantidad cada vez mayor de información generada diariamente. Redes sociales, dispositivos móviles, sensores de Internet de las Cosas (IoT), transacciones en línea, registros de navegación e incluso interacciones en sistemas internos son fuentes continuas de datos.
En este escenario, surge la necesidad de tecnologías capaces de almacenar, organizar y analizar este inmenso volumen de información de manera accesible y escalable. Es exactamente aquí donde entra el concepto de data lake.
El data lake se ha convertido en uno de los pilares fundamentales para la transformación digital y la evolución de las estrategias de análisis de datos. A diferencia de estructuras más rígidas, permite almacenar datos en sus formatos originales, ya sean estructurados, semi-estructurados o no estructurados, sin la necesidad de definir previamente esquemas de organización.
Para aquellos que desean entender a fondo el tema, en este artículo descubrirás qué es un data lake, cómo se diferencia de otras soluciones como el data warehouse, sus ventajas y desafíos, además de aplicaciones prácticas en empresas reales. ¿Vamos allá?
¿Qué es un Data Lake?
Antes de entender cómo aplicar y explotar los beneficios de un data lake, es esencial entender qué significa realmente este concepto. A menudo confundido con otras herramientas de almacenamiento, el data lake tiene características propias que lo hacen ideal para manejar datos modernos y a gran escala.
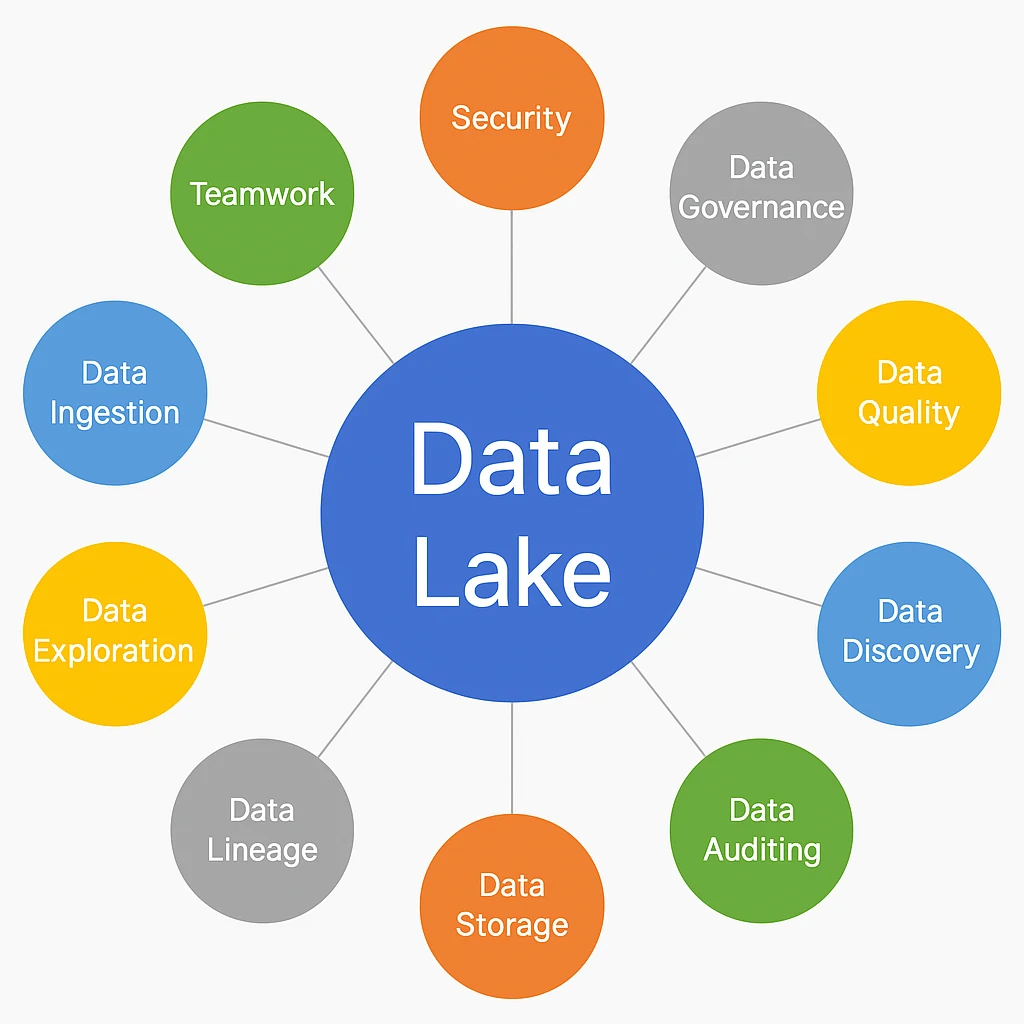
Definición y concepto
Un data lake puede ser definido como un repositorio centralizado que almacena datos en sus formatos originales, sin la necesidad de estructuración previa.
De manera práctica, esto significa que la información de diferentes fuentes puede consolidarse en un mismo espacio, lo que va desde hojas de cálculo y tablas relacionales hasta imágenes, vídeos, registros de sensores y registros de sistemas.
Historia del término
Para entender cómo llegamos hasta aquí, es interesante revisitar el momento en que surgió el término y ganó relevancia. El concepto de data lake no nació por casualidad, sino como respuesta a las limitaciones de los modelos tradicionales que no satisfacían las necesidades de la era del big data.
El término data lake fue popularizado en 2010 por James Dixon, entonces CTO de Pentaho. Utilizó la metáfora del lago para contrastar con el concepto de data mart.
Mientras que el mart se asemeja a botellas de agua embotellada, listas para consumir, el lago sería un cuerpo de agua natural, donde cualquier persona puede recolectar y utilizar el agua de acuerdo con su necesidad.
Data Lake vs. Data Warehouse
Para muchas empresas, una duda recurrente es la diferencia entre data lake y data warehouse. Aunque ambos se utilizan para almacenamiento y análisis de información, sus objetivos, estructuras y casos de uso son bastante distintos.
Schema-on-read vs. Schema-on-write
Uno de los puntos que más generan confusión está relacionado con la forma en que cada tecnología maneja los datos. Aquí es donde entran los conceptos de schema-on-read y schema-on-write, fundamentales para entender la flexibilidad de cada solución.
La principal diferencia entre data lake y data warehouse reside en cómo se almacenan y consumen los datos.
- Data warehouse: utiliza el concepto de schema-on-write. Es decir, los datos necesitan ser transformados y organizados en un esquema estructurado antes de ser almacenados, lo que garantiza consistencia y confiabilidad, pero reduce la flexibilidad.
- Data lake: sigue el modelo schema-on-read. En este caso, los datos se almacenan en su formato bruto y solo se organizan en el momento de la lectura o análisis. Esto proporciona una mayor adaptabilidad para explorar información no estructurada.
Casos de uso ideales
Después de entender la diferencia entre los modelos, surge la pregunta práctica: ¿cuándo usar un data lake y cuándo usar un data warehouse? Cada tecnología se adapta mejor a ciertos escenarios, y conocer estos casos ayuda en la toma de decisiones.
El data warehouse todavía es más adecuado para informes financieros, control operacional y análisis de datos ya estructurados, que requieren precisión y consistencia. Mientras que los data lakes brillan en escenarios que involucran:
- Grandes volúmenes de datos de diferentes fuentes (big data).
- Proyectos de aprendizaje automático e inteligencia artificial.
- Almacenamiento y análisis de datos no estructurados, como videos, imágenes y registros de IoT.
Para una comparación más didáctica, consulte la tabla que hemos preparado a continuación:

Ventajas del Data Lake
Los beneficios de un data lake se vuelven aún más claros cuando analizamos sus aplicaciones prácticas. Además de la flexibilidad, su escalabilidad y capacidad para soportar análisis avanzados ofrecen ventajas competitivas para empresas de diversos sectores.
Flexibilidad con diversos tipos de datos
La primera gran ventaja es precisamente la flexibilidad. Las empresas modernas no solo manejan hojas de cálculo o informes estructurados; necesitan integrar información proveniente de múltiples fuentes y en formatos completamente diferentes.
Una de las grandes ventajas del data lake es su capacidad para manejar múltiples formatos de datos: estructurados, semi-estructurados y no estructurados.
Escalabilidad y eficiencia de valores
Otro punto destacado es la escalabilidad. A medida que los datos crecen exponencialmente, tener una solución capaz de adaptarse sin costos prohibitivos es esencial para mantener la competitividad.
Como la mayoría de los data lakes modernos están basados en la nube, es posible almacenar volúmenes prácticamente ilimitados de información pagando solo por lo que se utiliza.
Suporte a análise avançada e inovação
Finalmente, una de las ventajas más estratégicas es la capacidad de alimentar análisis avanzados. Al centralizar datos brutos, el data lake crea un ambiente fértil para la experimentación e innovación.
El data lake es la base ideal para proyectos de inteligencia artificial y machine learning, además de permitir análisis predictivos y prescriptivos.
Es decir, en general, tendremos:

Desafios e riscos dos Data Lakes
A pesar de las ventajas, no podemos ignorar que los data lakes también presentan desafíos importantes. Sin una gestión adecuada, lo que debería ser un recurso estratégico puede convertirse en un dolor de cabeza.
A continuación, vamos enumerar algunos de los principales desafíos y riesgos involucrados con los data lakes.
Data Swamp: cuando el lago se convierte en pantano
El término data swamp surgió precisamente para alertar sobre los riesgos de un data lake mal gestionado. En lugar de generar valor, puede convertirse en un repositorio caótico e inútil. Y, seamos honestos: eso no es exactamente lo que aquellos que desean utilizar este recurso quisieran ver como resultado.
Gobernanza, seguridad y catalogación
Otro punto crítico está en la gobernanza. La ausencia de políticas claras de seguridad y catalogación puede comprometer la integridad de los datos y aumentar los riesgos de fugas.
Arquitectura y componentes de un lago de datos moderno
Entender la arquitectura de un data lake es esencial para darse cuenta de cómo organiza los datos de diferentes formas y garantiza la eficiencia de su uso. Después de todo, la división en capas y el uso de herramientas específicas hacen la gestión mucho más práctica.
Capas de almacenamiento
Uno de los pilares de esta arquitectura es la división en capas de almacenamiento, cada una con un propósito específico. Esto garantiza organización y claridad sobre el ciclo de vida de los datos.
Echa un vistazo a un poco más sobre este sistema en la siguiente tabla:

Herramientas de ingesta y catálogo
Además de las capas, el proceso de ingestión y catalogación es fundamental. Sin estas herramientas, los datos perderían valor por no estar accesibles o debidamente organizados.
Tecnologías de procesamiento
Por último, el procesamiento es el corazón que da vida al data lake. Son las tecnologías de análisis las que transforman los datos brutos en insights accionables.
Casos de uso en empresas reales
Entender la teoría es importante, pero nada reemplaza los ejemplos prácticos. Grandes empresas en sectores como logística, minorista y marketing ya utilizan data lakes para transformar sus operaciones y estrategias.
Big data y IoT
La combinación de big data e IoT es uno de los escenarios más comunes para la aplicación de data lakes. Millones de datos generados por sensores y dispositivos conectados solo tienen sentido cuando se centralizan y se analizan correctamente.
Análise de comportamento do cliente e marketing
En marketing, la personalización depende directamente del análisis integrado de diferentes canales. Es en este punto donde el data lake muestra su valor.
Data Lake no setor de varejo
El comercio minorista maneja un enorme volumen de datos de clientes, ventas, logística y comportamiento de compra. Empresas como Walmart utilizan data lakes para integrar datos de diferentes canales y, a partir de ahí, optimizar inventarios, predecir demandas estacionales y personalizar ofertas.
Data Lake no setor financeiro
Los bancos y fintechs también se benefician del Data Lake. El Banco Itaú, por ejemplo, adopta arquitecturas basadas en Data Lakes para cruzar millones de transacciones por minuto. Este proceso ayuda a detectar fraudes, evaluar riesgo de crédito y ofrecer productos personalizados.
Data Lake y HostGator: cómo aplicar
A menudo, las empresas asocian los data lakes solo con grandes corporaciones. Sin embargo, los proveedores de alojamiento y los negocios digitales también pueden aprovechar este modelo para optimizar sus resultados.
Recopilación y análisis de registros de acceso
Los registros de acceso son una mina de oro poco explorada. Consolidarlos en un data lake permite entender patrones y tomar decisiones más rápidas.
Optimización de sitios web y comercios electrónicos alojados
Además, el comportamiento del usuario en sitios alojados puede indicar cuellos de botella en la conversión o fallas en la experiencia que necesitan ser corregidas.
Seguridad reforzada
Otro punto esencial es la seguridad. Al cruzar datos de accesos y eventos, un data lake puede identificar amenazas en tiempo real.
¿Quieres saber un poco más sobre esto? Entonces consulta la siguiente tabla:

Tendencias futuras e innovaciones
El universo de los datos está en constante transformación. El concepto de data lake ya ha evolucionado hacia nuevos formatos y promete cambios significativos en los próximos años.
Data Lakehouse
La primera tendencia es la unión de dos mundos: el data lake y el data warehouse. Este modelo híbrido está ganando fuerza y promete ofrecer lo mejor de ambos, generando incluso una nueva nomenclatura: la data lakehouse.
Metadatos inteligentes y automatización
Otra innovación está en la automatización. Sistemas que utilizan inteligencia artificial para catalogar y organizar metadatos reducen el esfuerzo humano y aumentan la eficiencia.
Conclusión
El data lake es una solución estratégica para empresas que desean extraer valor de datos cada vez más variados y voluminosos. No reemplaza completamente otras tecnologías, pero amplía las posibilidades de innovación, análisis avanzados e integración entre diferentes fuentes de información.
Ya sea para big data, proyectos de machine learning o análisis de marketing, invertir en un data lake bien estructurado, con una gobernanza sólida y herramientas adecuadas, es un paso esencial hacia la transformación digital.
Echa un vistazo también: